- Views 4971×
- Blog home
-
Share on Twitter

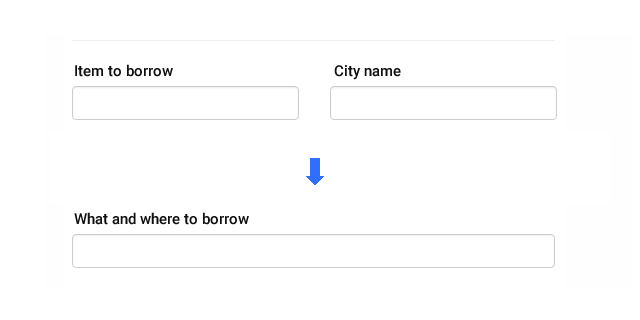
I like to find improvements and new ideas how to solve some task so the result will bring benefits. In one of my project I wanted to reduce two HTML form inputs to one and extract the city name from search text. Thanks to Rubix ML, I was able to tackle the task and practice named entity recognition in PHP, which was the main reason.
Let's recap the assignment:
- User will enter search term with or without city name
- City name can be at any position in term
- City name can consists of multiple words
- Model will expect raw term in lowercase letters
Project structure for ML task:
├── data │ └── dataset-20210404001.csv [496 kB] │ └── dataset-debug.csv │ └── dataset-test-20210404001.csv ├── model │ └── district-20210404001.model [2,01 MB] ├── report │ └── prior-20210404001.csv │ └── report-20210404001.json ├── vendor ├── composer.json ├── predict-one.php ├── test.php └── train.php
Translated to machine learning terminology, this task is supervised learning type from NLP field. The input feature is search term or short sentence, the output will be city name recognized from input. The city name will be limited group of city names, my set count 73 district names in Czech Republic.
As this is probably the simplest NLP task, I will use the Gaussian Naive Bayes classification algorithm for continuous features.
Before dive into ML project, it’s good to consider if the problem can be programmed directly in language you use. The solution may take less time, thus be cheaper.
Data set and data preprocessing
The success of ML project starts with data, and as Dr. Andrew Ng mentions in this video, it’s not that much about big data, just like a good data.
On project website, I’ve already logged search terms and city names entered by users. But for this task, with one feature, I will mix logged terms with synthetic terms just to create bigger data set. And of course I had to insert city names into the search terms randomly on different position. The result is that some samples has city name at the end, some at the start, some somewhere between. Remember to reflect data you expect to get in the feature.
So the final data set is CSV file with 15 000 samples. The Rubix CSV Extractor will import CSV data and create data set object for us. The Extractor expects last column in file to be the label.
dataset-20210404001.csv
Label is lowercased city name. The none label is where city name is not specified in the search term.
kalové čerpadlo hodonín;hodonín
hradec králové příkopové pažení;hradec králové
sanační bruska jablonec nad nisou;jablonec nad nisou
jičín kalové čerpadlo;jičín
hladička betonu rychnov nad kněžnou;rychnov nad kněžnou
koutoučová pila jihlava;jihlava
osvětlovací věže;none
tachov karavan;tachov
řezačka betonu jindřichův hradec;jindřichův hradec
elektrocentrála karlovy vary;karlovy vary
úhlová bruska semily;semily
vysavač sokolov;sokolov
kalové čerpadlo;none
strakonice čistič koberců;strakonice
Data set is split by 80% training, 20% validation ratio. I also created another data set for testing with data not similar to data during training.

Data preprocessing is important step in any machine learning project. It includes cleaning and formatting the data before feeding into a machine learning algorithm. For NLP, the preprocessing steps are comprised of the following tasks:
- Lower-casing (done before feeding into the model)
- Removing stop words, punctuation, urls (*)
- Stemming (**)
- Tokenizing the string
* In sentiment analysis, emotion icons have big impact on classification results.
** PHP stemming algorithm in Czech is not available yet.
Rubix ML has Transformers for data preprocessing. Transformer takes Data set object and modify the features. Series of Transformers can be used in transformer Pipeline. This is brilliant concept similar to Keras.
I used 3 transformers in pipeline:
- StopWordFilter
- WordCountVectorizer
- TfIdfTransformer
Note: I also tried ZscaleStandardizer(), but it had small impact on accuracy in this case, and the size of trained model was twice bigger then without ZscaleStandardizer().
WordCountVectorizer and TfIdfTransformer are very common for text preprocessing. TfIdfTransformer – (term frequency-inverse document frequency), is a numerical statistic that reflect how important a word is to a document, so it gives us some word weight. It expects that input is token frequency vectors. This is the result of WordCountVectorizer.
The WordCountVectorizer builds a vocabulary from the training samples and transforms text blobs into fixed length sparse feature vectors. With Ngram() instance in constructor we are telling how far back in the history of a sequence of words should we go.
Model training
Training is done in train.php file. The core of ML in Rubix is called Estimators and I choose simple and fast classification algorithm Naive Bayes, the version for continuous data types GaussianNB(). It also has a short prediction time.
When you use Naive Bayes to predict city name, the algorithm is estimating the probability for each class by using the joint probability of the words in classes. And model does not require setting any custom/hyper parameters.
By wrapping pipeline with PersistentModel we are able to interface our trained model with file system or other storage types. After training is done we can save trained model. The file size was 2 MB.
⎘ train.php
<?php
use Rubix\ML\Transformers\StopWordFilter;
use Rubix\ML\Extractors\CSV;
use Rubix\ML\Datasets\Labeled;
use Rubix\ML\Pipeline;
use Rubix\ML\Transformers\WordCountVectorizer;
use Rubix\ML\Transformers\TfIdfTransformer;
use Rubix\ML\Other\Tokenizers\NGram;
use Rubix\ML\Other\Loggers\Screen;
use Rubix\ML\Persisters\Filesystem;
use Rubix\ML\PersistentModel;
use Rubix\ML\CrossValidation\Metrics\Accuracy;
use Rubix\ML\Classifiers\GaussianNB;
use function Rubix\ML\array_transpose;
use Rubix\ML\Datasets\Unlabeled;
include __DIR__ . '/vendor/autoload.php';
$stopWords = array('a','z','od','u','při','k','na','nad','před','za','pro');
$dataset = 'dataset';
$fileVersion = '20210404001';
$logger = new Screen();
$logger->info('Loading CSV into memory');
$iterator = new CSV(__DIR__ . '/data/' . $dataset . '.csv', false, ';');
$dataset = Labeled::fromIterator($iterator);
[$training, $validation] = $dataset->stratifiedSplit(0.8);
$estimator = new PersistentModel(
new Pipeline([
new StopWordFilter($stopWords),
new WordCountVectorizer(1000, 2, 1000, new NGram(1, 2)),
new TfIdfTransformer()
], new GaussianNB()), new Filesystem(__DIR__ . '/model/district-' . $fileVersion . '.model'));
$estimator->setLogger($logger);
$estimator->train($training);
if (true === $estimator->trained()) {
$logger->info('Saving progress');
$prior = $estimator->priors();
Unlabeled::build($prior)->toCSV()->write(__DIR__ . '/report/prior-' . $fileVersion . '.csv');
$logger->info('Saving model');
$estimator->save();
$logger->info('Validation');
$accuracy = new Accuracy();
$prediction = $estimator->predict($validation);
$scoreNum = $accuracy->score($prediction, $validation->labels());
echo 'Accuracy is ' . (string) ($scoreNum);
}C:\www\rml.text>php train.php
[2021-04-04 20:38:33] INFO: Loading CSV into memory
[2021-04-04 20:38:33] INFO: Fitted Word Count Vectorizer (max_vocabulary: 1000, min_document_frequency: 2, max_document_frequency: 1000, tokenizer: N-Gram (min: 1, max: 2, word tokenizer: Word))
[2021-04-04 20:38:33] INFO: Fitted TF-IDF Transformer (smoothing: 1)
[2021-04-04 20:38:35] INFO: Saving progress
[2021-04-04 20:38:35] INFO: Saving model
[2021-04-04 20:38:35] INFO: Validation
Accuracy is 0.9891488640217
Note on PHP and memory during training
If you will train models on large data set or long sentences, I would recommend at least 16 GB of RAM. With 8 GB of RAM the operation system and some services on background can already take around 3-4 GB of memory, and you will end up with „Allowed memory size of XXX bytes exhausted“ soon during training.
Rubix is capable to learn in batches and with Online interface you can train on large datasets and reduce memory consumption. Another solution can perhaps be RubixML/Extras git repository, where TokenHashingVectorizer() transformer can be tested in your module, as it is light on memory.
Testing and monitoring
When training is done we can access computed values by additional methods. This depends on estimator type. GaussianNB() has a 3 methods prior(), means() and variances() which returns array type results. Visualization is not currently part of the Rubix ML project, but there are some intentions.
So If we would like to visualize data we can modify and export results to CSV for example and use some JS plotting library for that.
Testing is done in separated file test.php. There we will test trained model on separated data set file with 3650 samples/instances. I saved test result to JSON file.
⎘ test.php
<?php
use Rubix\ML\Extractors\CSV;
use Rubix\ML\Other\Loggers\Screen;
use Rubix\ML\Datasets\Labeled;
use Rubix\ML\PersistentModel;
use Rubix\ML\Persisters\Filesystem;
use Rubix\ML\CrossValidation\Reports\AggregateReport;
use Rubix\ML\CrossValidation\Reports\ConfusionMatrix;
use Rubix\ML\CrossValidation\Reports\MulticlassBreakdown;
include __DIR__ . '/vendor/autoload.php';
$logger = new Screen();
$logger->info('Loading data into memory');
$iterator = new CSV(__DIR__ . '/data/dataset-test-20210404001.csv', false, ';');
$test = Labeled::fromIterator($iterator);
$logger->info('Making predictions');
$estimator = PersistentModel::load(new Filesystem(__DIR__ . '/model/district-20210404001.model'));
$predictions = $estimator->predict($test);
$report = new AggregateReport([
new MulticlassBreakdown(),
new ConfusionMatrix()
]);
$result = $report->generate($predictions, $test->labels());
$result->toJSON()->write(__DIR__ . '/report/report-20210404001.json');
$logger->info('Report saved');
For testing is Rubix equipped with Report Generator interface. Depending on Estimator type you can generate report on test data set. And you can aggregate multiple reports wrapping them by AggregateReport class.
C:\www\rml.text>php test.php [2021-04-04 20:49:02] INFO: Loading data into memory
[2021-04-04 20:49:02] INFO: Making predictions
[2021-04-04 20:49:35] INFO: Report saved
⎘ report.json
"overall": {
"accuracy": 0.9999457288370767,
"accuracy_balanced": 0.9988588365813884,
"f1_score": 0.9987051987051987,
"precision": 0.9997297297297297,
"recall": 0.9977477477477477,
"specificity": 0.9999699254150293,
"negative_predictive_value": 0.9999725335091189,
"false_discovery_rate": 0.0002702702702702705,
"miss_rate": 0.002252252252252253,
"fall_out": 3.0074584970728067e-5,
"false_omission_rate": 2.7466490881124053e-5,
"threat_score": 0.9974774774774775,
"mcc": 0.9986937223914732,
"informedness": 0.9977176731627769,
"markedness": 0.9997022632388485,
"true_positives": 3650,
"true_negatives": 266450,
"false_positives": 3,
"false_negatives": 3,
"cardinality": 3650
}
Running on production
Rubix ML is really good concept and with RubixML/Server and RubixML/Tensor you have key tools to create production ready ML/Deep Learning project in PHP.
Rubix Server allows to run your trained Rubix ML models on network and wrap your trained estimator in an API that can be queried locally or over the network in real-time using standard protocols. In addition, the library provides async-compatible client implementations for making queries to the server from your PHP applications. Requests can be queried by REST and GraphQL APIs.
⎘ predict-one.php
<?php
include __DIR__ . '/vendor/autoload.php';
use Rubix\ML\PersistentModel;
use Rubix\ML\Persisters\Filesystem;
$estimator = PersistentModel::load(new Filesystem(__DIR__ . '/model/district-20210404001.model'));
$prediction = $estimator->predictSample(['řezačka betonu karlovy vary']);
echo 'City name: ' . $prediction;
C:\www\rml.text>php predict-one.php
City name: karlovy vary
I hope this post brings some intuition to beginners how to solve task where ML can by applied. PHP developers have tool that makes possible to implement advanced ML methods in PHP on production solutions. Rubix ML is currently at version 0.4 and still shaping it’s path. My big respect to Rubix team and the work they have already done.
The trained model is very dumb, because it just memorize categories/city names it has learned. But still can be usefull and it has its uses. More sophisticated methods comes from Part-of-speech tagging (POS).
Footnotes- What are N-grams
- Rubix ML
- RubixML/Tensor GitHub
- RubixML/Server GitHub